

亚马逊云科技 Free Tier 2.0 全面升级:$200抵扣金+6个月免费,零风险畅享云服务
在数字化转型不断加速的今天,云计算已经成为开发者、初创团队乃至大型企业不可或缺的基础设施。从个人博客搭建、Web 应用部署,到 AI 模型训练、数据分析与企业级系统运行,云服务几乎贯穿了整个技术生命周期。
为了让更多用户能够低成本、低风险地体验云服务,亚马逊云科技近年来持续推出免费套餐。尤其是最新的 Amazon Free Tier 2.0,作为升级版的免费体验计划,不仅优化了以往的不足,还在抵扣金机制、注册门槛、任务激励等方面全面提升,让上云体验变得更简单、更灵活、更安心。本文将从新旧对比、亮点解析、适用场景、注册流程等多个角度,带你深入了解这款全新的免费套餐。
一、为什么要关注 Amazon Free Tier 2.0?上云的第一步,往往是从体验开始。很多人对云计算的第一印象来自于免费套餐。过去,亚马逊云科技的免费套餐在功能上已经覆盖了多项常见服务,但存在一些问题:
额度分散:不同服务都有单独的免费配额,很多开发者实际只用到少数服务,导致剩余额度浪费;
误扣风险:一旦超出配额,便会进入计费阶段,新手用户往往难以及时察觉 ...
零门槛上云体验:Amazon Free Tier 2.0 全面升级,助力开发者与企业轻松上手
在当下数字化转型的浪潮中,云计算早已成为企业与个人开发者不可或缺的基础设施。从网站搭建到 AI 应用开发,从数据分析到企业级应用部署,云服务的身影无处不在。然而,对于很多初创团队或学生开发者来说,高昂的成本、复杂的计费模式、试错风险,往往成为“上云”的第一道门槛。
为了让更多用户能够低成本、低风险地体验云服务,亚马逊云科技近年来持续推出免费套餐。尤其是最新的 Amazon Free Tier 2.0,作为升级版的免费体验计划,不仅优化了以往的不足,还在抵扣金机制、注册门槛、任务激励等方面全面提升,让上云体验变得更简单、更灵活、更安心。本文将从新旧对比、亮点解析、适用场景、注册流程等多个角度,带你深入了解这款全新的免费套餐。
一、为什么要关注 Amazon Free Tier 2.0?上云的第一步,往往是从体验开始。很多人对云计算的第一印象来自于免费套餐。过去,亚马逊云科技的免费套餐在功能上已经覆盖了多项常见服务,但存在一些问题:
额度分散:不同服务都有单独的免费配额,很多开发者实际只用到少数服务,导致剩余额度浪费;
误扣风险:一旦超出配额,便会进入计费阶段,新手用户往往难以及时察觉 ...
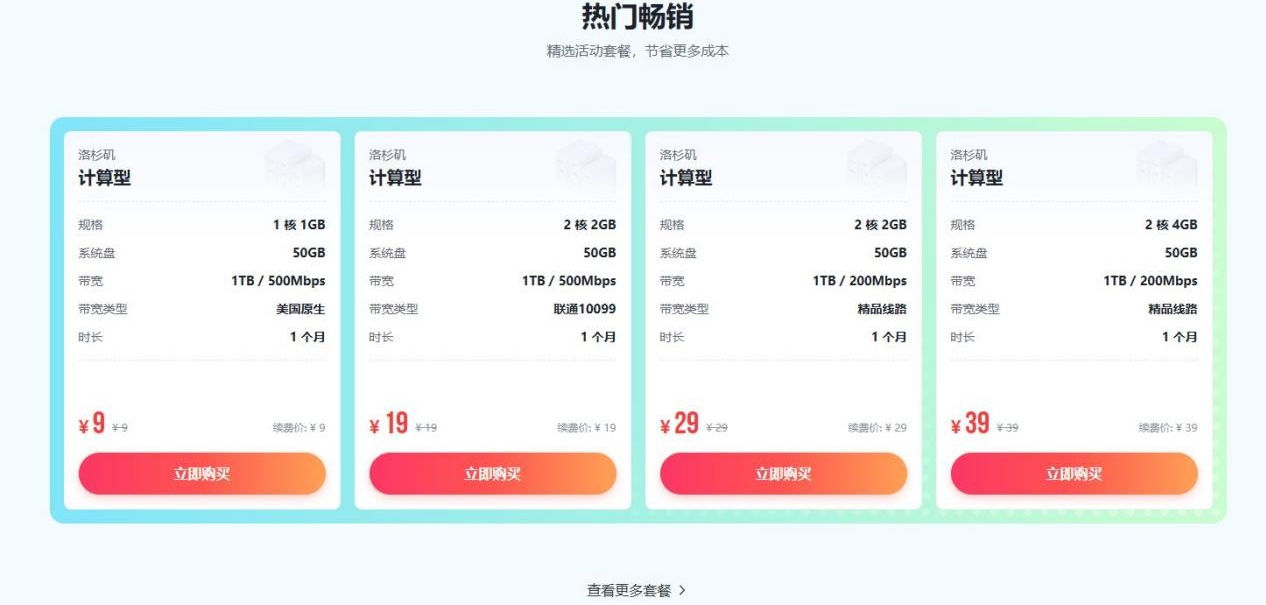
高性价比云服务器推荐:非凡云选购攻略
在当今数字化浪潮中,云服务器已成为个人开发者、企业及各类线上业务的核心基础设施。今天,给大家重点介绍一个表现亮眼的云服务提供商 —— 非凡云,分享其优势、高性价比套餐及适用场景,再讲讲购买流程,助大家轻松上云。
一、非凡云
非凡云是国内深耕互联网通信研发的专业云服务企业,从创立初期就锚定 “高品质云服务器” 赛道。
硬件基础上,非凡云直接入驻美国洛杉矶 EQUNIX T3 级数据中心(T3 级是数据中心的重要等级标准,意味着全年可用性达 99.982%,硬件故障时能通过冗余架构快速切换,避免业务中断);
资质合规上,它已经拿到增值电信业务经营许可证、《信息安全管理体系认证》、《信息技术服务体系认证》(ISO20000 认证),这三项资质是云服务企业的 “敲门砖”,尤其增值电信业务许可证,要求企业满足技术、资金、风控等多维度标准,不是随便就能拿到的;
技术能力上,持续投入资源研发创新,推出 AS9929 、移动精品等全新优质线路,优化网络传输,为用户带来高效稳定的云计算体验。其分布式存储系统通过三重数据备份机制,全方位保护用户数据。
二、高适配套餐:从个人到企业,总 ...
云上启航,从 0 成本开始:深入解读亚马逊云科技免费套餐的无限可能
引言在 AI、云计算和自动化技术爆发式增长的时代,开发者、创业公司乃至大型企业都在寻求更低门槛、更高效的方式迈入智能化新时代。对于许多初创者而言,启动成本始终是最大的挑战。幸运的是,亚马逊云科技通过其全面的免费套餐,正在为全球开发者打开一扇无需成本即可探索未来技术的大门。无论你是希望试验生成式 AI 项目、构建 Web 应用、部署服务器,还是想搭建数据分析平台,亚马逊云科技免费套餐都为你提供了入门级所需的一切基础服务与资源支持。本文将带你全方位了解亚马逊云科技免费套餐的内容、适用场景和实际用法,让你轻松上云,零门槛开启技术创新之路。
新用户可获得高达 200 美元的服务抵扣金亚马逊云科技新用户可以免费使用亚马逊云科技免费套餐(Amazon Free Tier)。注册即可获得 100 美元的服务抵扣金,在探索关键亚马逊云科技服务时可以再额外获得最多 100 美元的服务抵扣金。使用免费计划试用亚马逊云科技服务,最长可达 6 个月,无需支付任何费用,除非您选择付费计划。付费计划允许您扩展运营并获得超过 150 项亚马逊云科技服务的访问权限。
一、免费不限期?亚马逊云科技免费套餐三种模式 ...
打造物联网时代的智慧边缘:全面解锁亚马逊云科技边缘计算与 IoT 能力
引言随着万物互联时代的来临,智能制造、智慧城市、远程医疗、自动驾驶等场景对 实时计算、边缘处理、设备控制 提出了更高要求。传统的云计算虽然强大,但面对 海量设备、低延迟处理、局域控制需求 时,往往力不从心。
在这场 “云+边+端”融合的技术革命 中,亚马逊云科技通过其强大的 边缘计算平台、IoT 设备管理服务、云原生集成工具,为开发者和企业提供一整套从端侧到云端的智能解决方案。
本文将带你深入了解亚马逊云科技如何通过边缘计算 + IoT 服务,构建起支撑未来产业智能化的基础架构。
新用户可获得高达 200 美元的服务抵扣金亚马逊云科技新用户可以免费使用亚马逊云科技免费套餐(Amazon Free Tier)。注册即可获得 100 美元的服务抵扣金,在探索关键亚马逊云科技服务时可以再额外获得最多 100 美元的服务抵扣金。使用免费计划试用亚马逊云科技服务,最长可达 6 个月,无需支付任何费用,除非您选择付费计划。付费计划允许您扩展运营并获得超过 150 项亚马逊云科技服务的访问权限。
一、重新定义“云”:什么是边缘计算?边缘计算(Edge Computing)是一种在靠近数据源的物 ...
云上智能的未来:借助亚马逊云科技构建自动化与生成式 AI 的新时代
引言在人工智能全面爆发的今天,企业与开发者正以前所未有的速度迈向数字化转型。而在这场技术革新的浪潮中,生成式AI、大语言模型、自动化云原生架构正成为核心驱动力。作为全球领先的云计算平台,亚马逊云科技正在将前沿AI能力与强大的基础设施无缝结合,帮助从初创公司到大型企业加速构建智能应用,释放无限创新潜能。
今天,我们将深入探讨亚马逊云科技如何通过其大语言模型服务、自动化开发工具链、智能数据分析平台等产品,赋能开发者构建下一代智能系统。
新用户可获得高达 200 美元的服务抵扣金亚马逊云科技新用户可以免费使用亚马逊云科技免费套餐(Amazon Free Tier)。注册即可获得 100 美元的服务抵扣金,在探索关键亚马逊云科技服务时可以再额外获得最多 100 美元的服务抵扣金。使用免费计划试用亚马逊云科技服务,最长可达 6 个月,无需支付任何费用,除非您选择付费计划。付费计划允许您扩展运营并获得超过 150 项亚马逊云科技服务的访问权限。
一、迈入AI新时代:亚马逊云科技大语言模型服务介绍随着 ChatGPT、Claude、Midjourney 等生成式AI工具的普及,越来越多企业也开始 ...
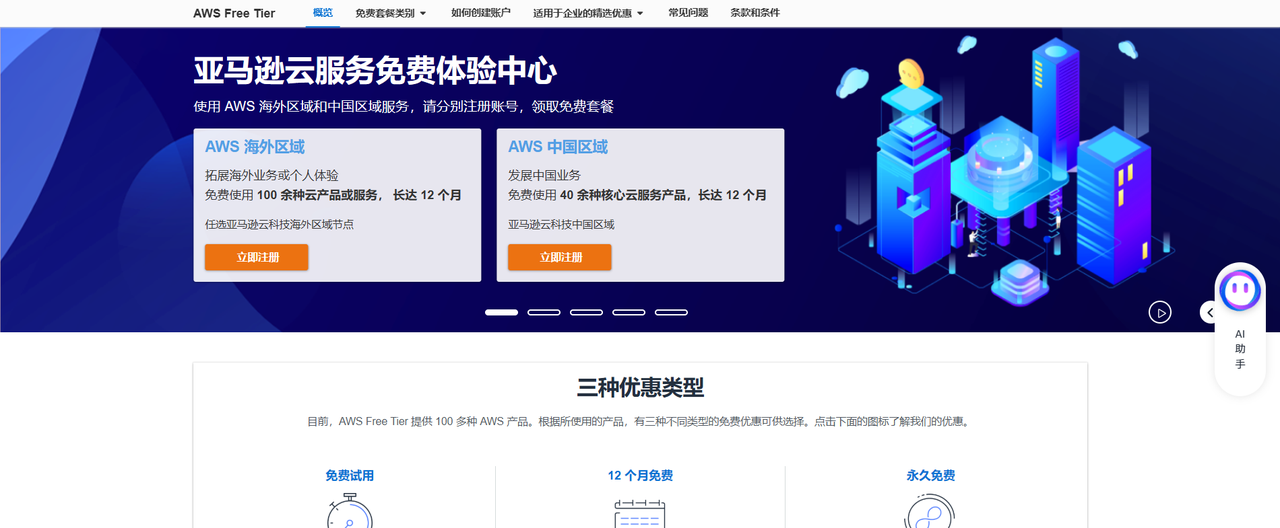
构建现代云上应用的第一步,从亚马逊云科技免费资源开始
在当今数字化加速演进的背景下,企业和开发者们面临着越来越多的技术选择与挑战。无论你是初创企业在寻找低成本、高弹性资源,还是成熟企业希望通过云服务优化运营效率,亚马逊云科技都提供了覆盖广泛的产品组合与解决方案。更重要的是,亚马逊云科技还为开发者、企业和学生提供了大量的免费云产品资源,为大家迈出“上云”的第一步提供了极大的便利。
想亲自体验这些资源?你可以访问:亚马逊云科技即可获取众多免费服务与优惠,真正实现低门槛、高灵活性的云端起步。
免费使用一年,不花一分启动云端项目许多用户对于“上云”这件事最大的顾虑往往来自成本压力。亚马逊云科技显然考虑到了这个问题,推出了为期一年的免费套餐,覆盖了包括云服务器、数据库、对象存储、内容分发网络等在内的多种基础设施产品。比如,用户可以免费使用 750 小时的 Amazon EC2 t2.micro 或 t3.micro 实例(根据地域差异可能略有不同),也就是说,你可以每天24小时不间断运行一台云服务器,持续整整一年。
此外,Amazon S3 提供了 5GB 的标准存储空间,适合存储网页图片、音视频资源、备份数据等内容。搭配 CloudFront 的 ...
探索亚马逊云科技:全面体验免费云产品与注册指南
很多人听说过亚马逊云科技有“永久免费套餐”,但具体能用来做什么?是不是只能试试水?用起来会不会被偷偷扣费?
这篇文章我将用 5 个真实场景告诉你:亚马逊云科技的免费资源不仅能帮你部署项目原型,甚至可以支撑一个轻量级的线上服务。文章结尾还附带一份实用的避坑指南,建议收藏。
👉 亚马逊云科技提供众多免费云产品,可以访问:亚马逊云科技
🚀 亚马逊云科技免费套餐五大实战场景详解✅ 场景一:零成本搭建高性能个人网站/博客✨ 核心免费服务组合
服务
免费额度
适用场景
Amazon S3
5GB 永久存储
托管静态网页(HTML/JS/CSS)
Amazon CloudFront
1TB/月 CDN流量 + 100万次请求
全球加速,降低延迟
Amazon Route 53
免费DNS解析(域名需自备)
绑定自定义域名(如 yourblog.com)
🔧 部署流程
生成静态网站:用 Hexo/Hugo 编译网页
上传至S3:开启「静态网站托管」功能
加速优化:配置CloudFront + 免费SSL证书
域名绑定:在域名商添加CNAME记 ...
用好亚马逊云科技免费套餐:五个实战场景带你零成本部署云端项目
引言随着数字化浪潮席卷全球,各类企业和开发者都在寻求低成本、高效率的云计算方案。在众多云服务提供商中,亚马逊云科技凭借其丰富的免费产品和灵活的计费模式脱颖而出。今天,我们将深入介绍亚马逊云科技的免费资源,并简单演示注册流程,助您快速上手!亚马逊云科技在免费云产品方面提供了诸多选择,是初学者和创业者的理想起点。
一、亚马逊云科技免费产品概览亚马逊云科技免费套餐专为新用户量身打造,覆盖计算、存储、数据库、网络、安全等方方面面,力求满足大多数中小型项目的试用需求。以下是部分核心免费产品介绍:
1. 计算类
弹性云服务器(ECS):提供 t4g.micro、t3.micro、t2.micro 等规格,配备 CPU、内存及网络资源,对轻量应用足够应付。
无服务器函数(Function Compute):无需管理服务器,即可运行代码——适用于响应式开发、微服务逻辑等。
容器服务:支持 Kubernetes 或 Docker 容器部署,适合微服务架构和 CI/CD 流程。
2. 存储类
对象存储(OSS):类似 S3,提供标准、低频、归档等存储类型,适合静态资源托管、数据备份等。
块存储(Dis ...
亚马逊云科技免费套餐:零门槛体验企业级云服务
云计算已成为现代企业及开发者不可或缺的技术基础设施,无论是搭建网站、运行应用程序,还是进行大数据分析,云服务都能提供高效、弹性的资源支持。作为全球领先的云计算平台,亚马逊云科技(Amazon Web Services, Amazon) 提供丰富的免费套餐(Free Tier),让用户无需任何成本即可体验企业级云服务。本文将详细介绍亚马逊云科技免费套餐的核心服务、适用场景,并附上详细的注册指南,帮助您快速上手。
亚马逊云科技中国峰会定于2025年6月19-20日在上海举办,汇集生成式AI、大数据等尖端技术。通过参与实践工作坊和专家分享会,您将掌握最新云计算趋势。立即报名,开启您的技术革新之旅!
PC报名链接小程序报名链接 #Amazon Summit #云计算创新
一、亚马逊云科技免费套餐包含哪些服务?很多人误以为“用云很贵”,但实际上,AWS 提供的免费套餐非常适合个人开发者、小型项目甚至初创企业进行低成本试验与部署。这个免费套餐一共分为三类:适用于新用户的12个月免费层、所有用户都可享的永久免费层,以及部分服务的短期免费试用。
在不同场景下,这三种免费层提供了丰富的计算、存储、 ...
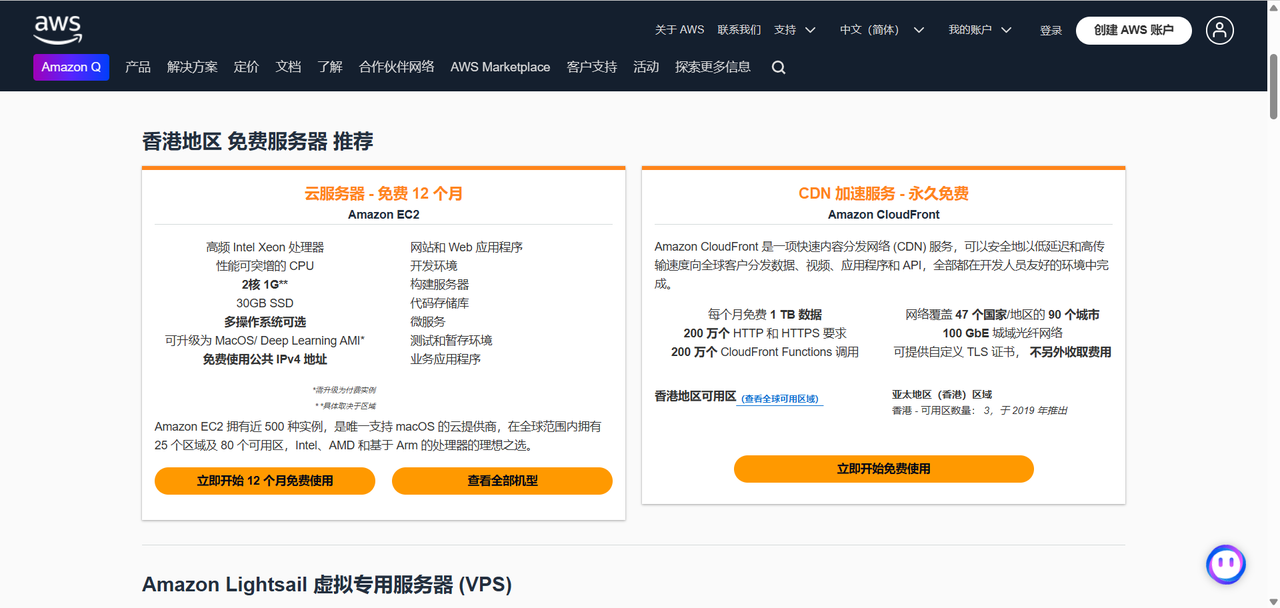
亚马逊云科技香港服务器:低延迟、高可用的亚太业务首选
在全球化数字经济的浪潮下,企业对于稳定、高效的云计算基础设施需求日益增长。亚马逊云科技(Amazon Web Services) 香港区域(ap-east-1)作为亚太地区的重要节点,为跨境企业、游戏公司、金融科技等行业提供了<50ms的中国大陆访问延迟,是拓展亚太市场的理想选择。
本文将详细介绍香港区域的核心优势、典型应用场景,并提供服务器部署指南,帮助您快速构建高可用的云端业务架构。
亚马逊云科技中国峰会定于2025年6月19-20日在上海举办,汇集生成式AI、大数据等尖端技术。通过参与实践工作坊和专家分享会,您将掌握最新云计算趋势。立即报名,开启您的技术革新之旅!
PC报名链接小程序报名链接 #Amazon Summit #云计算创新
一、为什么选择亚马逊云科技香港服务器?在亚太区域中,香港具备独特的地缘和通信优势。对于希望低延迟连接中国大陆、东南亚甚至全球市场的企业来说,Amazon 香港区域(ap-east-1)是一块性价比极高的“黄金跳板”。
网络性能:为跨境场景而生Amazon 香港区域的网络能力不仅体现在速度上,更体现在整体体验的平稳与可靠:
指标
数 ...



